|
Current: Research Scientist, Meta AI Previous: AI Lead @ Tesla Optimus |

|
|
Setup: Quadruped robot climbs on planks, sofa,and stairs then back down. Achieved completely from onboard cameras and compute without any preprogrammed gaits!
At CoRL'22 (Auckland, New Zealand) |
|
|
webpage |
abstract |
bibtex |
arXiv
Animals are capable of precise and agile locomotion using vision. Replicating this ability has been a long-standing goal in robotics. The traditional approach has been to decompose this problem into elevation mapping and foothold planning phases. The elevation mapping, however, is susceptible to failure and large noise artifacts, requires specialized hardware, and is biologically implausible. In this paper, we present the first end-to-end locomotion system capable of traversing stairs, curbs, stepping stones, and gaps. We show this result on a medium-sized quadruped robot using a single front-facing depth camera. The small size of the robot necessitates discovering specialized gait patterns not seen elsewhere. The egocentric camera requires the policy to remember past information to estimate the terrain under its hind feet. We train our policy in simulation. Training has two phases - first, we train a policy using reinforcement learning with a cheap-to-compute variant of depth image and then in phase 2 distill it into the final policy that uses depth using supervised learning. The resulting policy transfers to the real world without any fine-tuning and can traverse a large variety of terrain while being robust to perturbations like pushes, slippery surfaces, and rocky terrain.
@inproceedings{agarwal2022legged,
title={Legged locomotion in
challenging terrains
using egocentric vision},
author={Agarwal, Ananye and Kumar, Ashish
and Malik, Jitendra and Pathak, Deepak},
booktitle={6th Annual Conference
on Robot Learning}
}
|
|
|
webpage |
abstract |
bibtex |
arXiv
In this work, we show how to learn a visual walking policy that only uses a monocular RGB camera and proprioception. Since simulating RGB is hard, we necessarily have to learn vision in the real world. We start with a blind walking policy trained in simulation. This policy can traverse some terrains in the real world but often struggles since it lacks knowledge of the upcoming geometry. This can be resolved with the use of vision. We train a visual module in the real world to predict the upcoming terrain with our proposed algorithm Cross-Modal Supervision (CMS). CMS uses time-shifted proprioception to supervise vision and allows the policy to continually improve with more real-world experience. We evaluate our vision-based walking policy over a diverse set of terrains including stairs (up to 19cm high), slippery slopes (inclination of 35 degrees), curbs and tall steps (up to 20cm), and complex discrete terrains. We achieve this performance with less than 30 minutes of real-world data. Finally, we show that our policy can adapt to shifts in the visual field with a limited amount of real-world experience.
@article{loquercio2022learning,
title={Learning Visual Locomotion
with Cross-Modal Supervision},
author={Loquercio, Antonio and Kumar, Ashish
and Malik, Jitendra},
booktitle={arXiv preprint arXiv:2211.07638}
year={2022}
}
|
|
|
webpage |
abstract |
bibtex |
arXiv
Generalized in-hand manipulation has long been an unsolved challenge of robotics. As a small step towards this grand goal, we demonstrate how to design and learn a simple adaptive controller to achieve in-hand object rotation using only fingertips. The controller is trained entirely in simulation on only cylindrical objects, which then - without any fine-tuning - can be directly deployed to a real robot hand to rotate dozens of objects with diverse sizes, shapes, and weights over the z-axis. This is achieved via rapid online adaptation of the controller to the object properties using only proprioception history. Furthermore, natural and stable finger gaits automatically emerge from training the control policy via reinforcement learning.
@inproceedings{qihand,
title={In-Hand Object Rotation
via Rapid Motor Adaptation},
author={Qi, Haozhi and Kumar, Ashish
and Calandra, Roberto and
Ma, Yi and Malik, Jitendra},
booktitle={6th Annual Conference
on Robot Learning}
}
|
|
|
webpage |
abstract |
bibtex |
arXiv
This paper proposes a universal adaptive controller for quadcopters, which can be deployed zero-shot to quadcopters of very different mass, arm lengths and motor constants, and also shows rapid adaptation to unknown disturbances during runtime. The core algorithmic idea is to learn a single policy that can adapt online at test time not only to the disturbances applied to the drone, but also to the robot dynamics and hardware in the same framework. We achieve this by training a neural network to estimate a latent representation of the robot and environment parameters, which is used to condition the behaviour of the controller, also represented as a neural network. We train both networks exclusively in simulation with the goal of flying the quadcopters to goal positions and avoiding crashes to the ground. We directly deploy the same controller trained in the simulation without any modifications on two quadcopters with differences in mass, inertia, and maximum motor speed of up to 4 times. In addition, we show rapid adaptation to sudden and large disturbances (up to 35.7%) in the mass and inertia of the quadcopters. We perform an extensive evaluation in both simulation and the physical world, where we outperform a state-of-the-art learning-based adaptive controller and a traditional PID controller specifically tuned to each platform individually.
@article{zhang2022zero,
title={A Zero-Shot Adaptive
Quadcopter Controller},
author={Zhang, Dingqi and Loquercio, Antonio
and Wu, Xiangyu and Kumar, Ashish and
Malik, Jitendra and Mueller, Mark W},
journal={arXiv preprint arXiv:2209.09232},
year={2022}
}
|
|
|
webpage |
abstract |
bibtex |
arXiv |
demo
Recent advances in legged locomotion have enabled quadrupeds to walk on challenging terrains. However, bipedal robots are inherently more unstable and hence it's harder to design walking controllers for them. In this work, we leverage recent advances in rapid adaptation for locomotion control, and extend them to work on bipedal robots. Similar to existing works, we start with a base policy which produces actions while taking as input an estimated extrinsics vector from an adaptation module. This extrinsics vector contains information about the environment and enables the walking controller to rapidly adapt online. However, the extrinsics estimator could be imperfect, which might lead to poor performance of the base policy which expects a perfect estimator. In this paper, we propose A-RMA (Adapting RMA), which additionally adapts the base policy for the imperfect extrinsics estimator by finetuning it using model-free RL. We demonstrate that A-RMA outperforms a number of RL-based baseline controllers and model-based controllers in simulation, and show zero-shot deployment of a single A-RMA policy to enable a bipedal robot, Cassie, to walk in a variety of different scenarios in the real world beyond what it has seen during training.
@article{arma,
title={Adapting Rapid Motor
Adaptation for Bipedal Robots},
author={Kumar, Ashish and Li,
Zhongyu and Zeng, Jun and Pathak,
Deepak and Sreenath, Koushil
and Malik, Jitendra},
journal={IROS},
year={2022}
}
|
|
|
|
|
|
webpage |
pdf |
abstract |
bibtex
Legged locomotion is commonly studied and expressed as a discrete set of gait patterns, like walk, trot, gallop, which are usually treated as given and pre-programmed in legged robots for efficient locomotion at different speeds. However, fixing a set of pre-programmed gaits limits the generality of locomotion. Recent animal motor studies show that these conventional gaits are only prevalent in ideal flat terrain conditions while real-world locomotion is unstructured and more like bouts of intermittent steps. What principles could lead to both structured and unstructured patterns across mammals and how to synthesize them in robots? In this work, we take an analysis-by-synthesis approach and learn to move by minimizing mechanical energy. We demonstrate that learning to minimize energy consumption is sufficient for the emergence of natural locomotion gaits at different speeds in real quadruped robots. The emergent gaits are structured in ideal terrains and look similar to that of horses and sheep. The same approach leads to unstructured gaits in rough terrains which is consistent with the findings in animal motor control. We validate our hypothesis in both simulation and real hardware across natural terrains.
@article{fu2021minimizing,
author = {Fu, Zipeng and
Kumar, Ashish and Malik, Jitendra
and Pathak, Deepak},
title = {Minimizing Energy
Consumption Leads to the Emergence
of Gaits in Legged Robots},
journal= {Conference on Robot Learning (CoRL)},
year = {2021}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
Successful real-world deployment of legged robots would require them to adapt in real-time to unseen scenarios like changing terrains, changing payloads, wear and tear. This paper presents Rapid Motor Adaptation (RMA) algorithm to solve this problem of real-time online adaptation in quadruped robots. RMA consists of two components: a base policy and an adaptation module. The combination of these components enables the robot to adapt to novel situations in fractions of a second. RMA is trained completely in simulation without using any domain knowledge like reference trajectories or predefined foot trajectory generators and is deployed on the A1 robot without any fine-tuning. We train RMA on a varied terrain generator using bioenergetics-inspired rewards and deploy it on a variety of difficult terrains including rocky, slippery, deformable surfaces in environments with grass, long vegetation, concrete, pebbles, stairs, sand, etc. RMA shows state-of-the-art performance across diverse real-world as well as simulation experiments.
@article{kumar2021rma,
author = {Kumar, Ashish and
Fu, Zipeng and Pathak, Deepak
and Malik, Jitendra},
title = {RMA: Rapid Motor
Adaptation for Legged Robots},
journal= {RSS},
year = {2021}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv
Planning at a higher level of abstraction instead of low level torques improves the sample efficiency in reinforcement learning, and computational efficiency in classical planning. We propose a method to learn such hierarchical abstractions, or subroutines from egocentric video data of experts performing tasks. We learn a self-supervised inverse model on small amounts of random interaction data to pseudo-label the expert egocentric videos with agent actions. Visuomotor subroutines are acquired from these pseudo-labeled videos by learning a latent intent-conditioned policy that predicts the inferred pseudo-actions from the corresponding image observations. We demonstrate our proposed approach in context of navigation, and show that we can successfully learn consistent and diverse visuomotor subroutines from passive egocentric videos. We demonstrate the utility of our acquired visuomotor subroutines by using them as is for exploration, and as sub-policies in a hierarchical RL framework for reaching point goals and semantic goals. We also demonstrate behavior of our subroutines in the real world, by deploying them on a real robotic platform.
@article{kumar2019learning,
author = {Kumar, Ashish and
Gupta, Saurabh and Malik, Jitendra},
title = {Learning navigation
subroutines from egocentric videos},
journal= {Conference on Robot Learning (CoRL)},
year = {2019}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv
Humans routinely retrace paths in a novel environment both forwards and backwards despite uncertainty in their motion. This paper presents an approach for doing so. Given a demonstration of a path, a first network generates a path abstraction. Equipped with this abstraction, a second network observes the world and decides how to act to retrace the path under noisy actuation and a changing environment. The two networks are optimized end-to-end at training time. We evaluate the method in two realistic simulators, performing path following and homing under actuation noise and environmental changes. Our experiments show that our approach outperforms classical approaches and other learning based baselines.
@article{kumar2018visual,
author = {Kumar, Ashish
and Gupta, Saurabh and Fouhey, David
and Levine, Sergey and Malik, Jitendra},
title = {Visual Memory for
Robust Path Following},
journal= {NeurIPS},
year = {2018}
}
|
|
|
Repository |
pdf |
abstract |
bibtex |
arXiv
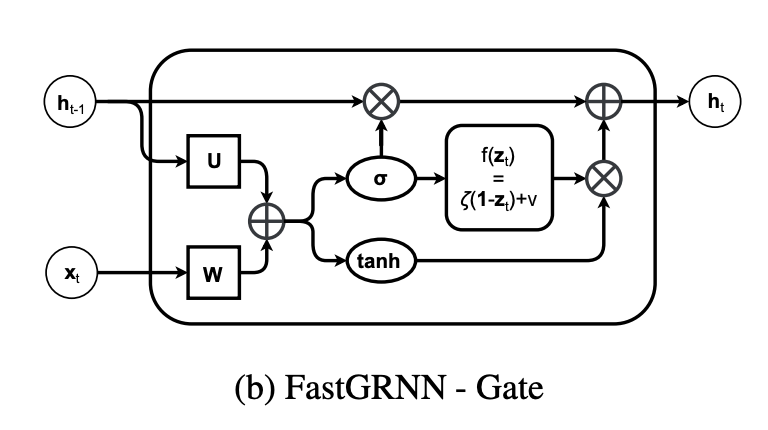
This paper develops the FastRNN and FastGRNN algorithms to address the twin RNN limitations of inaccurate training and inefficient prediction. Previous approaches have improved accuracy at the expense of prediction costs making them infeasible for resource-constrained and real-time applications. Unitary RNNs have increased accuracy somewhat by restricting the range of the state transition matrix's singular values but have also increased the model size as they require a larger number of hidden units to make up for the loss in expressive power. Gated RNNs have obtained state-of-the-art accuracies by adding extra parameters thereby resulting in even larger models. FastRNN addresses these limitations by adding a residual connection that does not constrain the range of the singular values explicitly and has only two extra scalar parameters. FastGRNN then extends the residual connection to a gate by reusing the RNN matrices to match state-of-the-art gated RNN accuracies but with a 2-4x smaller model. Enforcing FastGRNN's matrices to be low-rank, sparse and quantized resulted in accurate models that could be up to 35x smaller than leading gated and unitary RNNs. This allowed FastGRNN to accurately recognize the "Hey Cortana" wakeword with a 1 KB model and to be deployed on severely resource-constrained IoT microcontrollers too tiny to store other RNN models
@article{kusupati2018fastgrnn,
author = {Kusupati, Aditya and
Singh, Manish and Bhatia, Kush and
Kumar, Ashish and Jain, Prateek and
Varma, Manik},
title = {Fastgrnn: A fast, accurate, stable
and tiny kilobyte sized gated
recurrent neural network},
journal= {NeurIPS},
year = {2018}
}
|
|
Repository |
pdf |
abstract |
bibtex
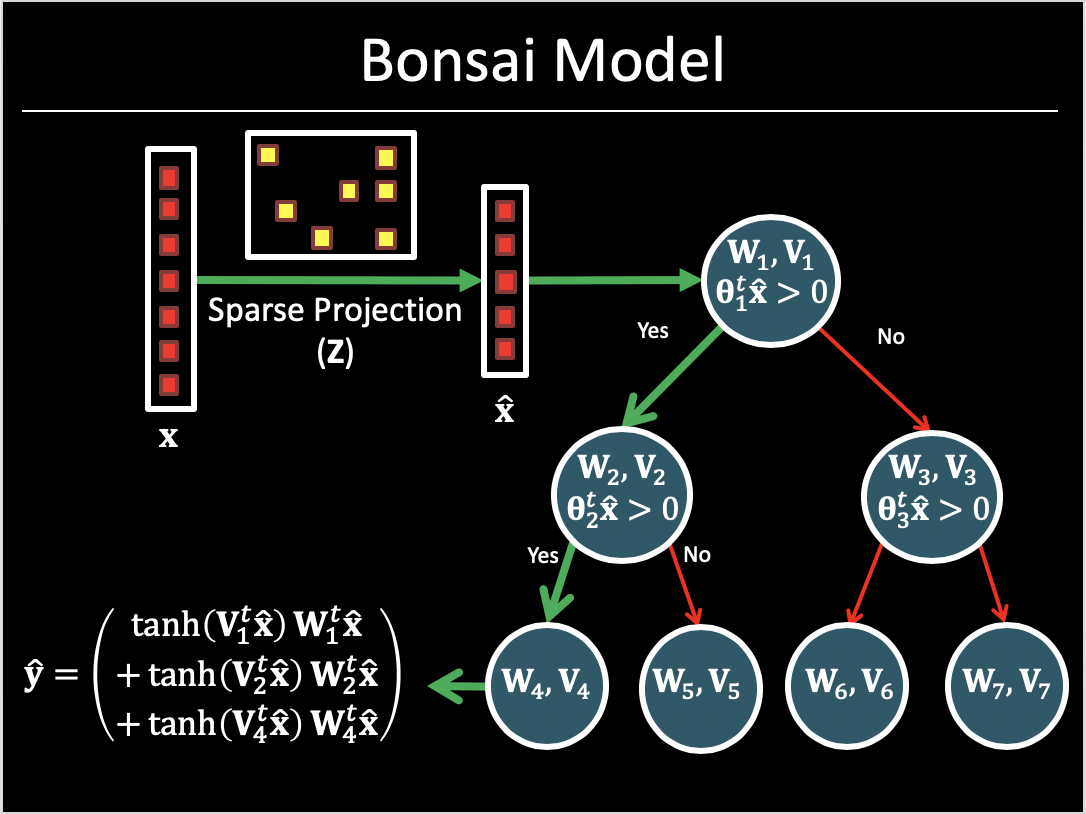
This paper develops a novel tree-based algorithm, called Bonsai, for efficient prediction on IoT devices – such as those based on the Arduino Uno board having an 8 bit ATmega328P microcontroller operating at 16 MHz with no native floating point support, 2 KB RAM and 32 KB read-only flash. Bonsai maintains prediction accuracy while minimizing model size and prediction costs by: (a) developing a tree model which learns a single, shallow, sparse tree with powerful nodes; (b) sparsely projecting all data into a low-dimensional space in which the tree is learnt; and (c) jointly learning all tree and projection parameters. Experimental results on multiple benchmark datasets demonstrate that Bonsai can make predictions in milliseconds even on slow microcontrollers, can fit in KB of memory, has lower battery consumption than all other algorithms while achieving prediction accuracies that can be as much as 30% higher than stateof-the-art methods for resource-efficient machine learning. Bonsai is also shown to generalize to other resource constrained settings beyond IoT by generating significantly better search results as compared to Bing’s L3 ranker when the model size is restricted to 300 bytes.
@article{kumar2017resource,
author = {Kumar, Ashish
and Goyal, Saurabh and Varma, Manik},
title = {Resource-efficient machine
learning in 2 KB RAM for
the internet of things},
journal= {ICML},
year = {2017}
}
|
|
Repository |
pdf |
abstract |
bibtex
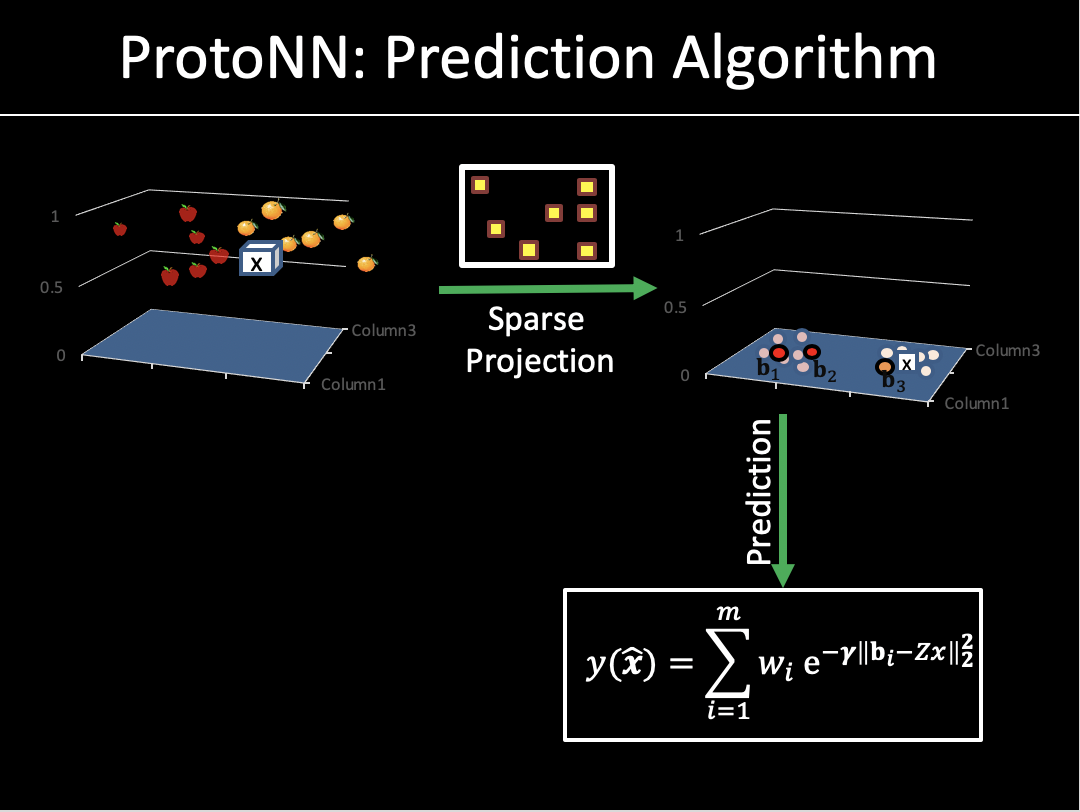
Several real-world applications require real-time prediction on resource-scarce devices such as an Internet of Things (IoT) sensor. Such applications demand prediction models with small storage and computational complexity that do not compromise significantly on accuracy. In this work, we propose ProtoNN, a novel algorithm that addresses the problem of real-time and accurate prediction on resource-scarce devices. ProtoNN is inspired by k-Nearest Neighbor (KNN) but has several orders lower storage and prediction complexity. ProtoNN models can be deployed even on devices with puny storage and computational power (e.g. an Arduino UNO with 2kB RAM) to get excellent prediction accuracy. ProtoNN derives its strength from three key ideas: a) learning a small number of prototypes to represent the entire training set, b) sparse low dimensional projection of data, c) joint discriminative learning of the projection and prototypes with explicit model size constraint. We conduct systematic empirical evaluation of ProtoNN on a variety of supervised learning tasks (binary, multi-class, multi-label classification) and show that it gives nearly state-of-the-art prediction accuracy on resource-scarce devices while consuming several orders lower storage, and using minimal working memory.
@article{gupta2017resource,
author = {Gupta, Chirag
and Suggala, Arun Sai and
Goyal, Ankit and Simhadri, Harsha Vardhan and
Paranjape, Bhargavi and Kumar, Ashish and
Goyal, Saurabh and Udupa, Raghavendra and
Varma, Manik and Jain, Prateek},
title = {Protonn: Compressed and accurate
knn for resource-scarce devices},
journal= {ICML},
year = {2017}
}
|
|
|
Sky dive : Lompoc, California -- 13000 feet Bungy Jump : Rishikesh, India -- 83m |
 |
 |
 |